由 judy , 1 九月 2021 Xilinx 携手魔视智能助推汽车前视摄像头创新 赛灵思与魔视智能今日宣布,双方正合作推出一款面向汽车市场的解决方案。它将赛灵思车规级( XA ) Zynq® 片上系统( SoC )平台与魔视智能的卷积神经网络( CNN )IP 相结合,专门用于前视摄像头系统的车辆感知与控制。
由 judy , 26 八月 2021 用于卷积神经网络的 DPUCAHX8H (v1.0) 本文描述 DPUCAHX8H,这是一种用于具有 HBM 的 Alveo 卡的高吞吐量 CNN 推理 IP。DPUCAHX8H 针对小图像尺寸网络进行了优化。
由 judy , 24 八月 2021 用于 Versal ACAP 的 DPUCVDX8G (v1.0) 本文介绍 DPUCVDX8G,这是一种可配置的计算引擎,针对具有 AI 引擎的 Versal ACAP 设备中的卷积神经网络进行了优化。
由 judy , 12 八月 2020 卷积神经网络能用 INT4 为啥要用 INT8 ?- 最新白皮书下载 对于 AI 推断,在提供与浮点媲美的精度的同时,int8 的性能优于浮点。然而在资源有限的前提下,int8 不能满足性能要求,int4 优化是解决之道。通过 int4 优化,与现有的 int8 解决方案相比,赛灵思在实际硬件上可实现高达 77% 的性能提升。
由 judy , 10 七月 2020 【下载】在Xilinx器件上具有INT4优化的卷积神经网络 INT8提供了比浮点数更好的性能,精度可与AI推论相比。但是,如果INT8在有限的资源下无法满足所需的性能,则INT4优化就是答案。通过INT4优化,与当前的INT8解决方案相比,Xilinx可以在实际硬件上实现高达77%的性能提升。
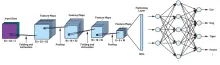
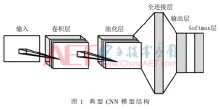
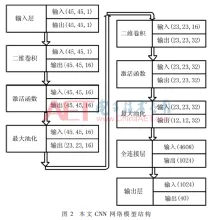
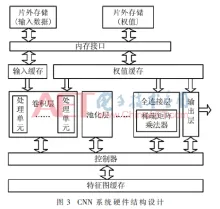
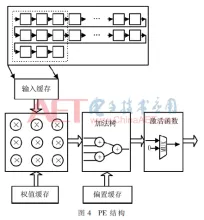
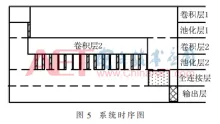
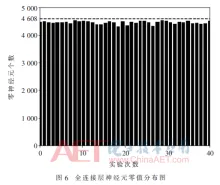
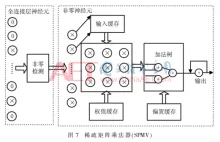
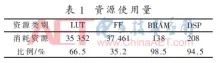
由 judy , 25 三月 2020 基于FPGA加速的卷积神经网络识别系统 针对卷积神经网络(CNN)在通用CPU以及GPU平台上推断速度慢、功耗大的问题,采用FPGA平台设计了并行化的卷积神经网络推断系统。通过运算资源重用、并行处理数据和流水线设计,并利用全连接层的稀疏性设计稀疏矩阵乘法器,大大提高运算速度,减少资源的使用
由 demi , 13 二月 2019 【视频】在PowerVR Series2NX NNA上进行动态推理演示 在训练一个神经网络时,“离线的”和可以实时识别新对象的训练模型(称为“推理”)之间是有区别的,例如,如果一个神经网络设计成用来识别过往的图片,例如一只猫,那么就需要从数千张猫的图像数据库中了解到猫是什么样的。 经过适当的训练,当你给一个有神经网络的设备展示猫先生的图片时,即使它以前没有见过猫它也能够认出猫,这就是推理。
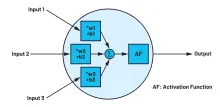
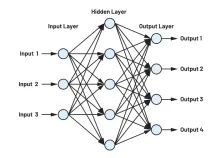
由 judy , 14 八月 2018 卷积神经网络的最佳解释 CNN由由可学习权重和偏置的神经元组成。每个神经元接收多个输入,对它们进行加权求和,将其传递给一个激活函数并用一个输出作为响应。整个网络有一个损失函数,在神经网络开发过程中的技巧和窍门仍然适用于CNN。很简单,对吧? 那么,卷积神经网络与神经网络有什么不同呢? <center><img src="http://xilinx.eetrend.com/files-eetrend-xilinx/article/201808/13270-386…; alt=""></center> 和神经网络输入不同,这里的输入是一个多通道图像(在这种情况下是3通道,如RGB)。





{kind=link}