TVM
TVM编译器
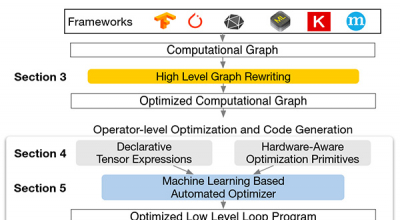
TVM最大的特点是基于图和算符结构来优化指令生成,最大化硬件执行效率。其中使用了很多方法来改善硬件执行速度,包括算符融合、数据规划、基于机器学习的优化器等。它向上对接Tensorflow、Pytorch等深度学习框架,向下兼容GPU、CPU、ARM、TPU等硬件设备。
TVM最大的特点是基于图和算符结构来优化指令生成,最大化硬件执行效率。其中使用了很多方法来改善硬件执行速度,包括算符融合、数据规划、基于机器学习的优化器等。它向上对接Tensorflow、Pytorch等深度学习框架,向下兼容GPU、CPU、ARM、TPU等硬件设备。